
Inhaltsverzeichnis
Wenn man beginnt, sich mit dem Themenfeld des maschinellen Lernens auseinander zu setzen, trifft man – egal aus welcher Perspektive auf das Thema geschaut wird – auf einige Statements bezüglich der benötigten Daten:
- Daten sind das A und O
- Die Datenbeschaffung und -aufbereitung ist meistens wesentlich aufwendiger als der eigentliche Aspekt des maschinellen Lernens
Wieso ist das so?
Erstens werden problemspezifische Daten benötigt. Das ist relativ eindeutig, da wenn ich eine Bilderkennungssoftware entwickeln möchte, welche Autos ihren Herstellern zuweisen soll, Autobilder als Verweis dienen. Ein Mensch könnte hier ja auch nicht bestimmen, welcher VW Golf vor ihm steht, wenn die einzige Referenz für die Aufgabe, die der Person zur Verfügung steht, ein Buch über Elefanten ist.
Zweitens ist es wichtig zu wissen, auf welche Weise unser Programm lernt. Dies ist relevant, weil es aussagt, welche Informationen in den problemspezifischen Daten enthalten seien müssen. Die unterschiedlichen Lernarten sind wie folgt:
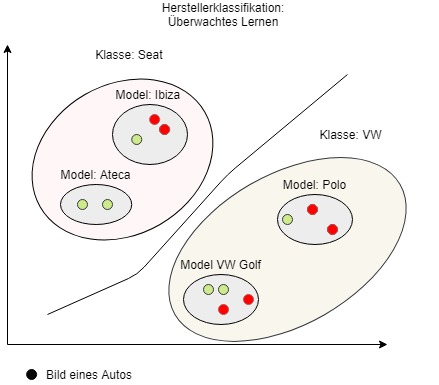
Supervised Learning (Überwachtes Lernen)
Beim überwachten Lernen wird dem Programm vorgegeben, was gelernt werden soll. Bei unserem Klassifizierungsproblem wird den Autobildern also hinzugefügt, nach was unterschieden werden soll, z.B. Hersteller, Form, usw.. Die Bilddaten müssen deswegen noch gelabelt, also mit zusätzlichen Informationen versehen werden. Das Programm verbindet dort die spezifischen Varianten und Informationen aus den Bildern mit der Zusatzinformation aus dem Label, z.B. alle Autos des Labels VW haben ein VW-Logo.
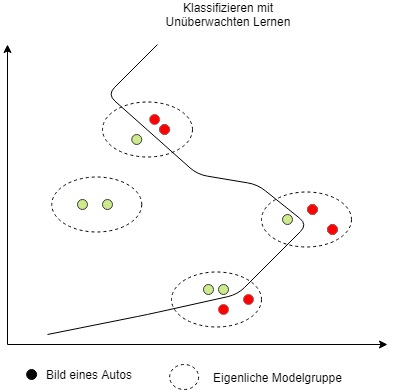
Unsupervised Learning (Unüberwachtes Lernen)
Beim unüberwachten Lernen versucht das Programm z.B. anhand der Daten eigene Gruppierungen von ähnlichen Bildern zu finden. Allerdings hat der Entwickler wenig Einfluss, was für Gruppierungen entstehen. Das Programm kann wie gewünscht nach Hersteller klassifizieren, aber es ist auch gut möglich und wahrscheinlicher, dass andere Elemente wie Form, Farbe, usw. prägnanter erscheinen und unser Programm auf einmal Autos daran unterscheidet, ob sie Rot oder Grün sind.
Semi-Supervised Learning (Halb-Überwachtes Lernen)
Beim halb überwachten Lernen versucht man einen Mittelweg zwischen den beiden Varianten zu finden. Ein Teil der Daten wird mit Labels versehen, allerdings versucht das Programm trotzdem auch mit den nicht gelabelten Daten zu lernen. Da das Labeln von Daten schnell sehr aufwendig und kostenintensiv sein kann und das Nutzen von nicht gelabelten Daten meist sehr ungenau ist und nicht das gewünschte Ergebnis erreicht, kann so, durch mittelmäßigen Aufwand, eine recht performante Lösung gefunden werden.
Zusammengefasst, es gibt keine Variante, die immer richtig und zielführend ist. Meistens lohnt es sich von den vorhandenen Ressourcen und der Problemstellung nach zu entscheiden. Wenn die Aufgabe des Programms sehr genau definiert ist und es sich keine Fehler erlauben kann, muss man ggf. in den sauren Apfel beißen und die gesamten Daten labeln, da so wahrscheinlich das genaueste Ergebnis erzielt wird. Wenn man noch gar nicht weiß, welche Labels überhaupt vorkommen, ist die Nutzung von unüberwachten Lernmethoden durchaus sinnvoller, bevor wichtige Features aus den Daten vom Menschen nicht vorher erkannt wurden und somit vom Programm nicht beachtet werden.


